The base for the analysis is the timespan of 9 year . It strats from November 2009 and follows untill November 2018. The hashtags analysis was performed both on all set of hashtags and hashtags written in English. Total number of unique hashtags used is approximatelly 72 thousand. At the same time, total number of unique hashtags written using latin alphabet is approximattely 56 thousand.
TF-IDF
In order to calculate the TF-IDF (term frequency–inverse document frequency) for the each hashtag, we processed data so that we had list of all the hashtags that were used for each day (with repetitions) during the specified period. At the same time, we created a list that contained every unique hashtag for the whole period.
The results for the whole set of the tweets is displayed in the Figure 1 (image to the right). The size of the word depends on it's TF-IDF value. It can be observed that #СПБ (Russian abbreveatio for Saint-Petersburg). More than that, large part of the largest words are Russian.
The second word is #news, followed by #новости (news), #sport, #politics . As the result, most of the top words are pretty generic, including #music, #crime, #tech etc. If we go down the list, we can find some hashtags that are related to events or heavily disscussed topic, for example, #ДНР (Donetsk People's Republic), #Крым (Сrimea), #НевскиеНовости (news portal located in Saint-Petersburg), #Украина (Ukraine) etc.
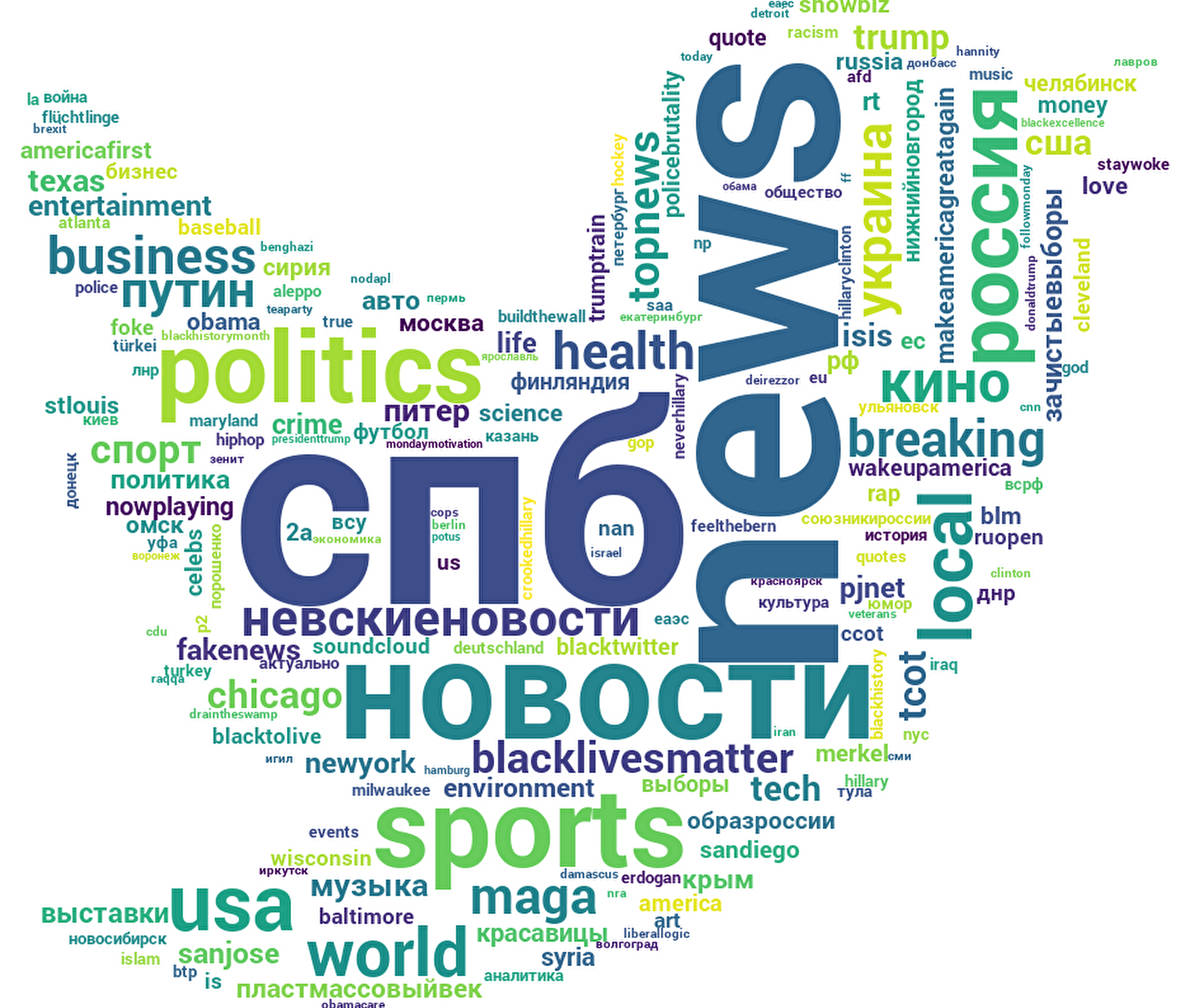
Figure 1: TF-IDF for full set of hashtags
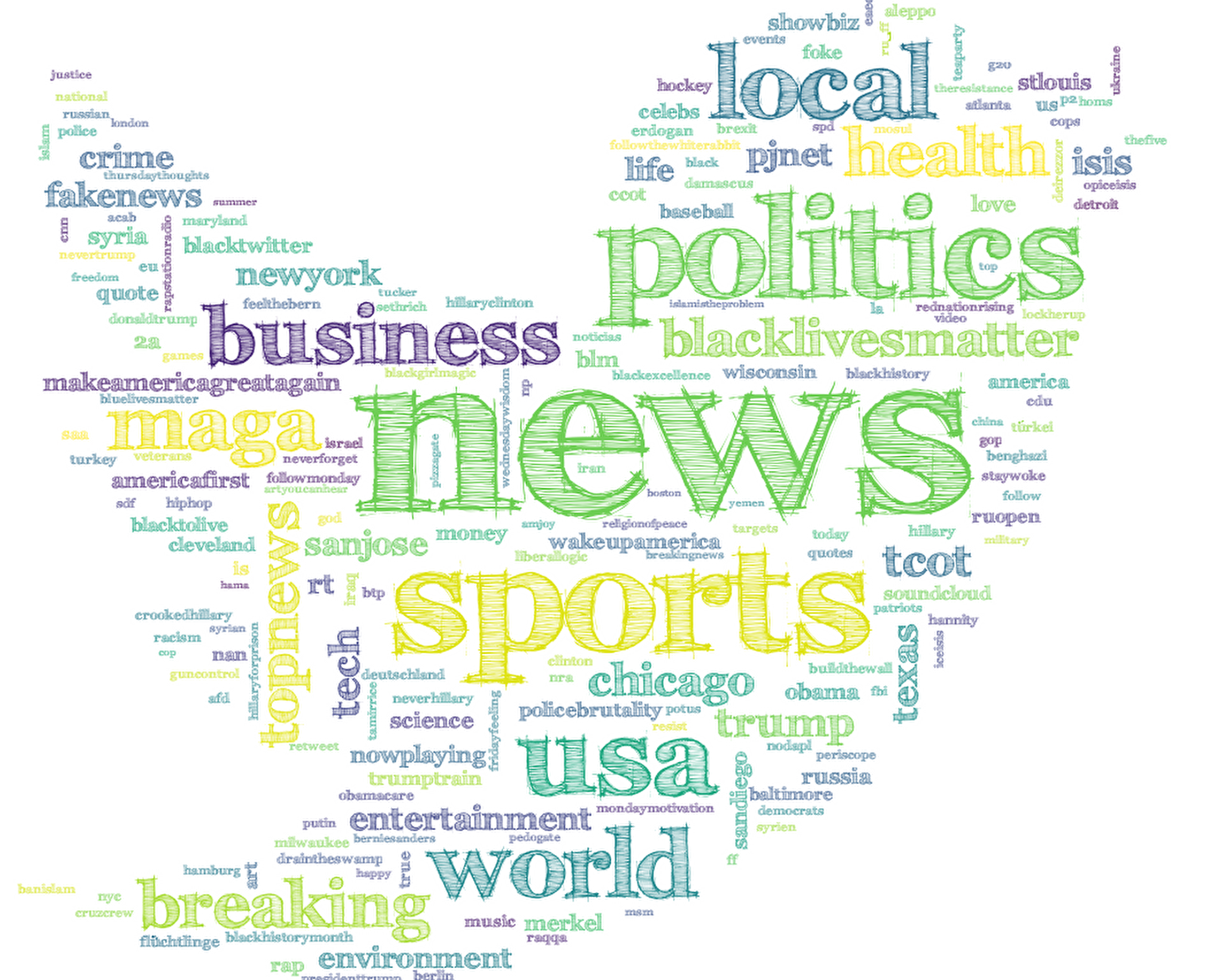
Figure 2: TF-IDF for English set of hashtags
Same is true, if we perform calculate TF-IDF only on hashatgs that are written using latin alphabet (see, Figure 2). Cloud is full of generic hashtags such as #news, #sports, #usa, #world, #local, #politics and etc.
However, if we go down the list we can observe hashtags as #policebrutality, #blacktolive, #americafirst, #trump, #makeamericancreatagain and more.